入门最后一站: OSX 搭建 Hadoop 开发环境¶
Well, 这是入门到放弃系列的最后一篇,以后就是修行在个人了。
Here We Go !
工欲善其事,必先利其器¶
好的工具给你高杠杆,来个华丽的撑竿跳,就可日行千里。
在代码的生命周期里,划分了不同的阶段,简单来说,就是开发阶段和开发之后的阶段(每个阶段都有一套最佳实践)。
开发阶段的时候,代码只不过是个玩具。开发阶段之后,就是从玩具到工程化的蜕变。(这么多阶段形成的以Github为起点的开发生态圈,活跃着无数IT企业)
简单来说,我们需要一个集成开发环境(IDE) 和 项目工程管理工具。
俺使用的IDE 是 Eclipse, 使用 Maven 进行 安装依赖,构建,发布等流程。
照猫画虎,运行你的 Hello World¶
游泳是看不会的,编程也是如此。我们从 Hadoop 的示例程序 WordCount 程序开始吧。
- 在 Eclipse 创建一个 Maven 项目, 命名 learn_hadoop
- 新建一个 Java 文件 App.java
- 把示例代码一行一行抄过来(为啥要一行一行呢?当然是要让你想想,每行代码会发生什么)。
- 尝试运行
好吧,我当然知道它运行不成功,如果不是的话,你真是撞大运了。
就我来说,一个真正的野生程序员来说,我从官网上复制粘贴的示例代码
有 50% 概率会直接报错,一行行鲜红日志触目惊心。
有 30%则会静默的退出,不给我任何解释。
有 10% 的会弹框 “电脑缺乏 F**c*K依赖” 。
有 5% 会提示我重启试试。
还有 3% 的代码一旦运行,机器会卡死。
剩下 2% 的能运行,可是打印的全是 “Hello World” 。
Life is always tough, Let’s fuck it ! (此处安利一下 homebrew, pyfuck 等良心软件)
Debug, Don’t Panic !¶
对, 我运行第一个 MapReduce wordcount 程序没有成功。
这是它的第一个错误 :
Error_01
log4j:WARN No appenders could be found for logger .
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info
还不算太糟,它给出了一点和日志有关的提示。日志不知道怎么输出,那么应该是少了什么配置。Google 之后发现 log4j 是个高级货,是Java程序员必备良品。
其实牛人写程序时打日志其实是很有讲究的,日志不仅是 BUG 的最后一颗救命稻草,也是运维监控必备,这一点在分布式系统里尤其重要。
所以俺对实习生的代码 review 都强调了日志的重要性。
于是我在项目添加了一个 log4j.properties 文件,调成 DEBUG 模式,只能期望看日志不会对着消防水管吃水。
Error_02
17/05/11 22:22:16 DEBUG learn_hadoop.App:
17/05/11 22:22:16 DEBUG security.UserGroupInformation: PrivilegedAction as:wenter (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.connect(Job.java:1306)
17/05/11 22:23:13 INFO mapreduce.Cluster: java.util.ServiceLoader[org.apache.hadoop.mapreduce.protocol.ClientProtocolProvider]
17/05/11 22:25:12 INFO mapreduce.Cluster: org.apache.hadoop.mapred.LocalClientProtocolProvider@e041f0c
17/05/11 22:25:49 INFO mapreduce.Cluster: [org.apache.hadoop.mapred.LocalClientProtocolProvider@e041f0c]
17/05/11 22:26:05 DEBUG mapreduce.Cluster: Trying ClientProtocolProvider : org.apache.hadoop.mapred.LocalClientProtocolProvider
17/05/11 22:26:43 INFO mapreduce.Cluster:
17/05/11 22:26:45 INFO mapreduce.Cluster:
17/05/11 22:26:57 INFO mapreduce.Cluster:
17/05/11 22:27:27 DEBUG mapreduce.Cluster: Cannot pick org.apache.hadoop.mapred.LocalClientProtocolProvider as the ClientProtocolProvider - returned null protocol
17/05/11 22:28:02 DEBUG security.UserGroupInformation: PrivilegedActionException as:wenter (auth:SIMPLE) cause:java.io.IOException: Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses.
Exception in thread "main" java.io.IOException: Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses.
at org.apache.hadoop.mapreduce.Cluster.initialize(Cluster.java:143)
at org.apache.hadoop.mapreduce.Cluster.<init>(Cluster.java:108)
at org.apache.hadoop.mapreduce.Cluster.<init>(Cluster.java:101)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1311)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1307)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1807)
at org.apache.hadoop.mapreduce.Job.connect(Job.java:1306)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1335)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1359)
at learn_hadoop.App.main(App.java:78)
对于比较长的日志,我们应该高兴,要是只有一行`you fucked up` 的日志,那才束手无策。
所以,打日志真的是很重要,程序的日志体现出了程序员的水准。
这段日志打印出了调用栈信息,初始化 Hadoop 集群信息出错,而且还是 IO Exception 。
很有可能是网络连接问题。
于是乎,俺仔细检查了配置,确认集群配置信息正确。然而,并没有解决这个问题。Google 了一下,有找到类似问题。
有的文章说是缺乏 hadoop mapreduce common client 的包,然并卵。
所以说,Google 找到的答案,不能全信而不管三七二十一就去试试,浪费精力。
当然一些通用的问题,能找到不错的答案。我们还是要具体问题具体分析。
接下来,只有靠自己了。
结构清晰,设计优良的代码,DEBUG 起来也不是啥难事。Hadoop 里的大部分代码都有注释,这点很有帮助。
于是我点进出错代码,却显示看不了源代码。
我又 Google 了一下,发现要把 maven 的依赖包Jar 文件 增加引用源。这样我们就能点进出错信息查看代码(Eclipse Jar 文件小奶瓶出现 📃 的小图标)。
加上断点之后,结合源代码和日志,发现了一条新线索,“Trying ClientProtocolProvider : org.apache.hadoop.mapred.LocalClientProtocolProvider ”
可以看到俺的程序尝试使用 “LocalClientProtocolProvider” 这个服务,也就是说我的程序总是在尝试连接本地的Hadoop,没有连接虚拟机里的集群。
我在 Hadoop mapreduce client jar 包里 的 META-INF文件夹看到 service 目录,的确有一个 “org.apache.hadoop.mapreduce.protocol.ClientProtocolProvider”文件打开后,里面配置是 “org.apache.hadoop.mapred.LocalClientProtocolProvider”
所以说,Java 加载的客户端不对。
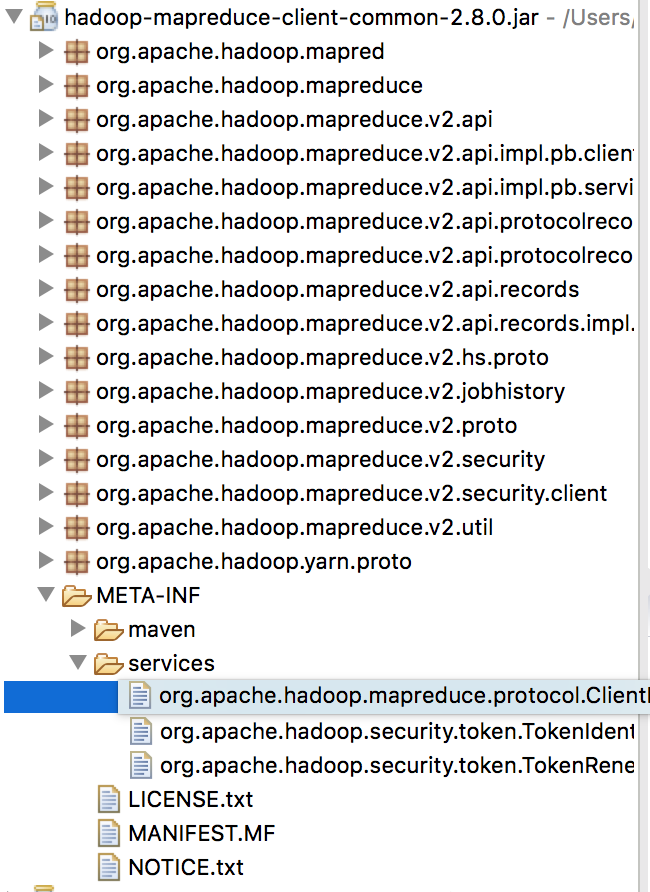
仔细查看之后发现common jar 包只有 LocalProvider。
那么能够连接远程Hadoop集群的客户端应该是在其他包里。
最后,我在 maven 的包管理 文件 pom.xml 里增加了 一个依赖:
Hadoop MapReduce Client:
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-jobclient -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.8.0</version>
</dependency>
终于,本地 Hadoop 的应用终于加载了正确的服务,连上了虚拟机的 Hadoop 集群。Bingo!
Summary¶
Okay, 我们已经入门了。接下来呢?
注:¶
俺调试这个程序花了一周的工作日晚上,遇到的错误当然也不只两个。大部分错误还是可以看日志解决的。
由于对 Java 不熟(上周才学Java),所以调试进展不是很快,期间屡有放弃的念头。人干嘛要这么折腾呢?
花了不少时间读 Maven 文档,Hadoop 文档,还有 看 Core Java 书籍。
对一个软件的架构有了一定了解之后,Debug 的时候也会有些头绪。
还有一个是 Debug 的时候,不能超过 1 小时,时间太长,脑子就会纠结于细节问题,也会淹没于各种网络信息。导致只看见树木,不见森林。
总结起来就是:
- 多看书,多看文档,以达到对事物有个大概总体的认识。
- 多出去走走。保持精神通畅,给自己信心。有效治愈气馁,失望情绪。