MapReduce, 大数据处理的基石¶
| keywords: | hadoop MapReduce |
|---|
为什么我们需要 MapReduce ?¶
每当我看见长城时,总不免心生感慨,这得需要多少人多少年才能完成这么大的工程啊!
然而,长城建造伊始,并不是一开始就连起来的,而是一小段一小段的拼接而成。
这种分而治之的思想,在我们学习归并排序的时候,就应熟稔于心。
同样的,在每一刻,对互联网企业(现在还有什么面向终端消费者的企业没有搭上互联网呢?)来说,客户都会产生大量的数据。而且是非结构化的,不是一般 Excel 小能手就能解决的。
这时候,我们就需要一个并行的,批处理的数据处理。
MapReduce 应运而生。
Hadoop 的 MapReduce 是怎么 Work 的 ?¶
上篇说到,Hdfs 是大数据的基石(存储)。而 MapReduce 则是运行其上的灵魂,是从无序中建造有序。
那 Hadoop 是怎么完成这一任务的?
欢迎来到大数据汉堡结构的倒数第二层,数据处理层。
让我们一起看看 Yarn (Yet Another Resource Negotiator) 的齿轮是如何运转的吧。
Yarn 的设计理念,在于把资源管理和任务管理分开。相当于一个公司,有管理部门和业务部门。
所以业务部门是任劳任怨的,管理部门有分配不公的可能性。
Yarn 资源管理节点是 Resource Manager, 业务管理节点是 NodeManager 。
举个例子来说明 Yarn 是如何工作的吧。
假如,现在股东(公司在资本市场都是为股东工作的),要求公司提高业绩。这个时候管理(Resource Manager)部门,也就是一群拍脑袋的家伙,算出需要多少资源,分配给了业务部门。
业务管理部门(Node Manager)也是有小老板的,小老板立刻招了几个实习生成立了项目组(Application Master) 。
项目组再规划出完成这件事,需要先切分成几个小任务(Task),分配给几个临时工。等这个项目完成了。项目组解散了。连五险一金都不用交,真是万事大吉。
来看个高清大图吧:
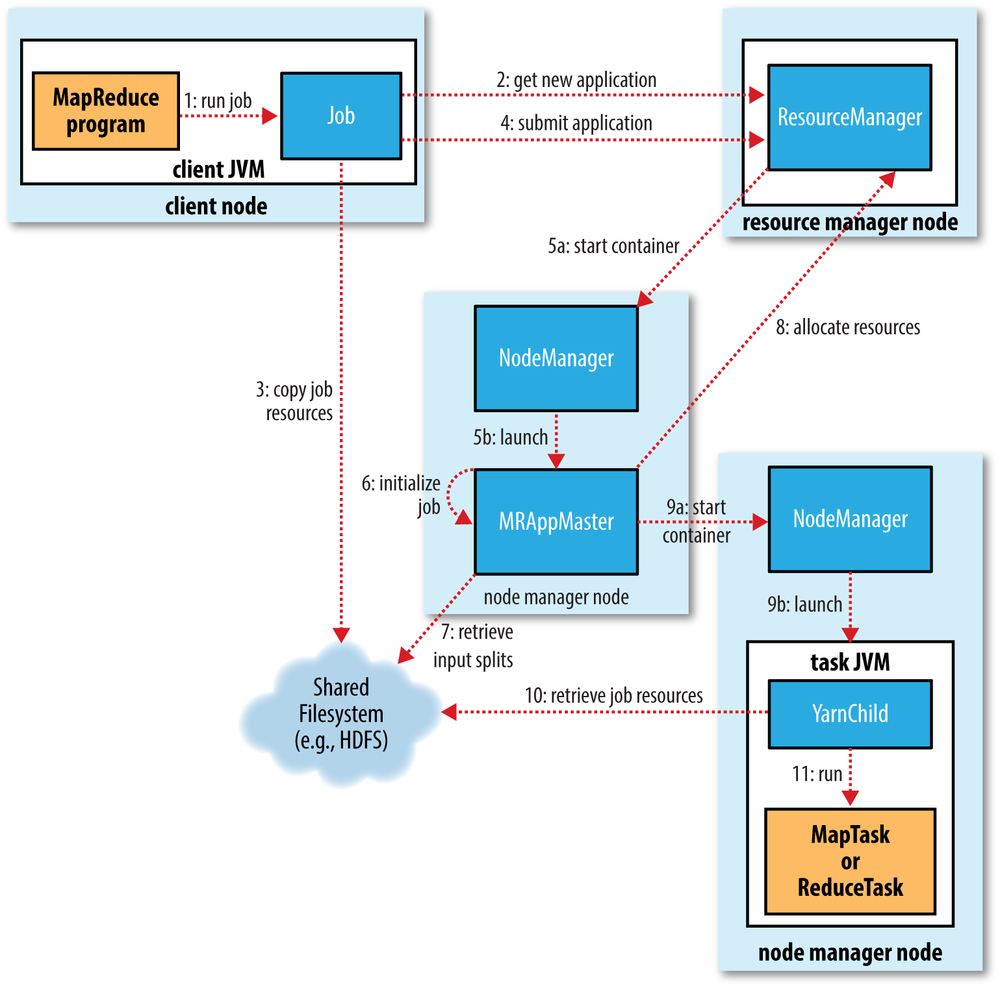
Yarn 启动¶
鉴于俺的电脑内存有限,没有闲钱加大我的内存,加大带宽。只能把 3 台虚拟机 改成 2 台了。
Yarn 有两个节点,分别是 Resource Manager: 10.10.10.1 , Node Manager: 10.10.10.2 。
Resource Manager 节点用默认配置,不需要改东西。
Node Manager 需要 配置 yarn-site.xml 和 mapred-site.xml 。
Node Manager:
yarn-site.xml (需要指定一下 resource manager 的主机)
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-1</value>
</property>
</configuration>
mapred-site.xml (只需要设置调度框架为 yarn)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
在 hadoop-1 节点启动 Resource Manager : yarn resourcemanager
在 hadoop-2 节点启动 Node Manager : yarn nodemanager
现在来运行你的第一个数字数的程序吧!¶
- Reference:
- Hadoop:The Definitive Guide, 4th Edition